How to debug and solve a big production problem with SaaS
Incident response protocols from experience at tech startups

Engineer, Builder, Writer
Software development is mostly not actually writing software. Sometimes it’s debugging a critical issue that cannot wait and is beyond abilities of first-line support. Keep reading to learn what tools you can and should employ when dealing with a long-running hard-to-fix problems.
You may be guarded by countless level of corporate hierarchy but eventually you will either be asked to debug a production issue or you will be in a job that will require it.
This article is aimed primarily at software engineers but also QAs, managers, leads, solution engineers.
How does an issue reach you?
You get an invite to a call, you’re tagged in jira ticket, on slack, or DM’ed. Ok, cool.
Someone is asking you to drop a feature you’ve been working on, switch context and help. Annoying, I know. Give yourself 90 seconds for grief and move on.
If someone is asking you for urgent help with production issue, they mean it.
Before you start, make sure your direct superior/manager/leas knows you are switching priorities.
And if you start investigating, make sure everyone knows it, so other people are not wasting time doing the same.
As you’ll see, comms are the key.
Communication
Before we get to any technical tips, let’s start with communication. I’ll mention some tools, some should be a part of the system already in place, automatic procedures. If they’re not, you should introduce them.
Incident slack channel
If you’re reading this in early XXI century, you have a company chat app.
Make sure there is a channel where all the people that can help with the problem or need information about it have a place to talk. Invite people and ask them to add anyone interested.
Spam this channel with progress updates.
Example name: inc-2023-01-04-sign-up-down . It can also include a ticket number instead of a date.
Cadency
Depending on the criticality of the issue, post summaries of what’s going on.
- If it’s an urgent issue that is classified as P1 (priority 1, critical system down, significant financial impact), you’re likely to post summaries each hour or two.
- If it’s a long running issue with lower priority, begin the day with the plan for what’s next and close the day with progress summary.
Message template
Here’s what I use:
Summary of [name/ticket] incident investigation as of 4PM, Jan 18th
Resolved: yes/no/partially
∑ Brief summary
- we know that the cause of the issue is: …
- fix by … didn’t work, we’re trying …., estimated test at …
- replication is hard, streamlining it
⏭️ Next steps
- […]
🧠 Other notes
- [ideas and resources]
These updates may not get reactions but many people will read them and quietly thank you for your thoroughness. If you are a recipient of those, like them, react with 👀 emoji, or whatever. Feedback is always good.
Forward daily updates on the main channel for issue discussions or on the team channel, so people less involved but still interested or able to help can see them.
Escalation
Whenever you are stuck - flag it and ask for help. You have an important task, it’s not worth being quiet. If your direct manager isn’t listening - try their manager.
When asking people for help, state how urgent is the question and when you need it done.
Don’t sit alone on an unresolved issue. You work with other specialists, present your idea to someone, get feedback.
Getting essential information
There are few types of information you are going to need. Apart from what comes with your programming experience.
- How to reproduce the issue? Steps taken, environment details.
- Input and output data - input that is causing the issue, the erroneous output, the right output.
- Logs with real-world examples of the issue in the wild.
- System knowledge - think knowing the part of the product in question, documentation.
- Initial estimate of impact on customers.
If you lack any of these at the start, work hard to get them first. I’ve been asked to work on a bug that no one could reproduce a few times. Customers that encountered it, didn’t have time to jump on a call. Imagine how hard it was to work on such an elusive problem.
You are OK to push back in these situations. Make sure to be collaborative with your customer-facing colleagues that will help gather this information. If you can, tell them exactly what you need. You can use the list above.
Regarding the point 5, estimating impact, it will need to be done properly either by you or someone else in the end. It will be needed for proper customer communication.
Working on the issue
Finding and fixing a bug is a little bit like doing science. You are likely going to follow a process like this:
- Construct a hypothesis
- Test it by doing experiments
- Analyze your data and draw a conclusion
- Come up with a fix
- Test the fix
- If it doesn’t work → repeat
Make sure to write down your current hypothesis and log any additional ideas. Keep track of what you checked and what you didn’t. If the work will end up taking long time or you’ll be forced to hand it over to someone else, these notes will be extremely useful.
In general, maintain a log of what you experimented with. This will help you avoid running in circles and providing good updates for the team.
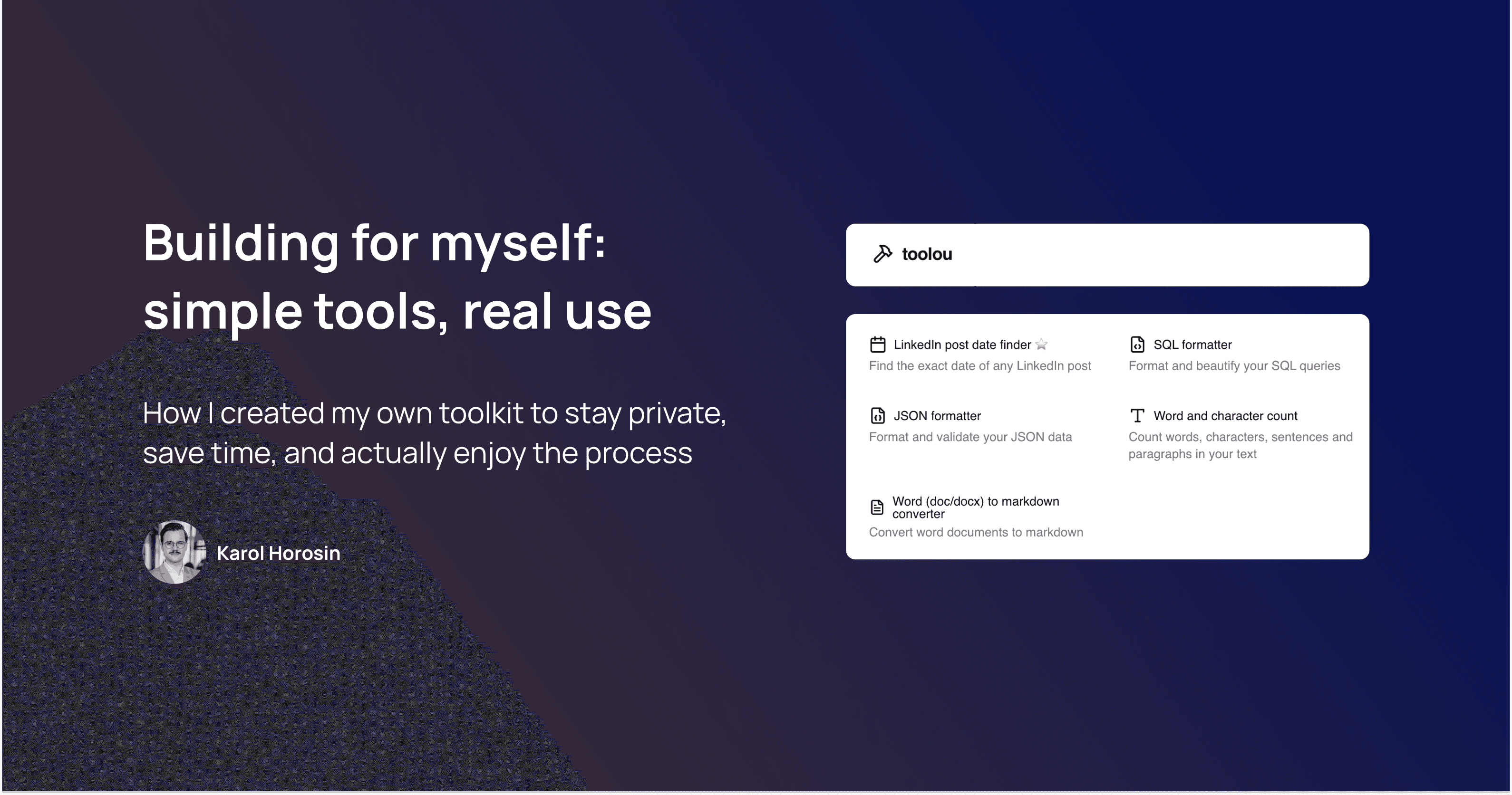
Create tools!
Whenever an experiment requires manual labour and you have to do it multiple times, create small tools helping you do it. As an example, if experimenting requires decrypting some values stored in your system, create a piece of code that will do that en masse instead of using online tools and console programs all the time.
If you need to parse some files and you are opening tens of them and looking for clues - create a small JS website that will help you extract the right information.
Mini-tools will help you move faster and you won’t need to repeat the same work. Of course make them only when it is necessary.
At many projects of mine, these tools later became a part of regular testing and development processes.
After the incident
Your company likely will have a process, usually it is called RCA - Root Cause Analysis. Someone should schedule a meeting with all of the people involved in the work and prepare a document, later distributed to everyone interested.
On top of this note, relevant work preventing such incidents in the future should be scheduled.
The point of the whole exercise is to learn from mistakes.
This meeting should not be geared towards blaming individuals. It should point out where the processes failed.
When everything is fixed, make sure everyone knows it is the case.
If you spent some extra hours working on it, ask to be compensated or to be able to work less in the coming days. Make sure to note down what you did and how it helped the company and use it on your next evaluation meeting.
Summary
If you have dealt with production issues at your job, this guide probably sounds familiar. If you are yet to be asked to fix something, this article gives you the proper frame of mind.
Remember:
- communication is the key, don’t neglect it
- fixing a bug is like doing scientific research, form and test hypotheses, note everything down
- create tools that will help you with manual work
- take and give credit, forget about the blame
What are your experiences with troubleshooting live issues?
If you liked this content, please support me by sharing this post and subscribing to my Newsletter.
You can also find me here: