Extracting and Generating JSON Data with OpenAI GPT, LangChain, and Python
Manipulating Structured Data (from PDFs) with the Model behind ChatGPT, LangChain, and Python for Powerful AI-driven Applications

K
Engineer, Builder, Writer
Search for a command to run...
Manipulating Structured Data (from PDFs) with the Model behind ChatGPT, LangChain, and Python for Powerful AI-driven Applications
Engineer, Builder, Writer
it's a detailed article with all useful information. i fine-tuned gpt3.5 with train and valid sets, i got the result file but i don't know how to analyse it! as the train accuracy column values fluctuate with 0.333 - 0.66 - 0,66-0- 0,66- 1e-05- 0-0.66-0.7-1 . does this mean i need more samples for training ?
what do you mean? what were you training for? what was your testing methodology?
i training gpt3.5 for binary classification task i would like to know the accuracy of fine-tuned model. i got a csv file which include 4 columns [step train_loss train_accuracy valid_loss valid_mean_token_accuracy] but the accuracy values is fluctuated is that mean my model doesn't work as appropriate ?
Ware you following any tutorial? How big is your set? Do results look OK when you test manually? Hard to help with limited info!
Karol Horosin sorry it wasn't your tutorial. I was confused. but kindly if you have knowledge about fine-tune gpt3.5 on binary classification task. i have a more than 200 000 samples. i think i will need just part of it.
Thanks for sharing this detailed breakdown! Sure it'll be useful for a lot of folks building similar apps in AI
Yeah there's still very limited resources on these tools. Especially there's a lack of good examples online
have.9.62
very, y tr h jnn j
This is a great approach but not flexible between LLMs. It should bo more optimal prompt size wise. For function calling, I would use openai Python package directly.
Karol Horosin any tips on how to do this right?
Coder Bible Ill think about a separate article. In the meantime, I've prepared a demo of function calling. Not for data extraction but instead of calling a function you can just take the input and use it in your application.
https://github.com/horosin/openai-functions-demo
In this blog series, we explore the transformative potential of artificial intelligence tools and models in software development and other fields via tutorials and case studies.
Hands-on example and tutorial to achieve shorter prompts, better performance and save money on your API calls. All using synthetic data from GPT-4.
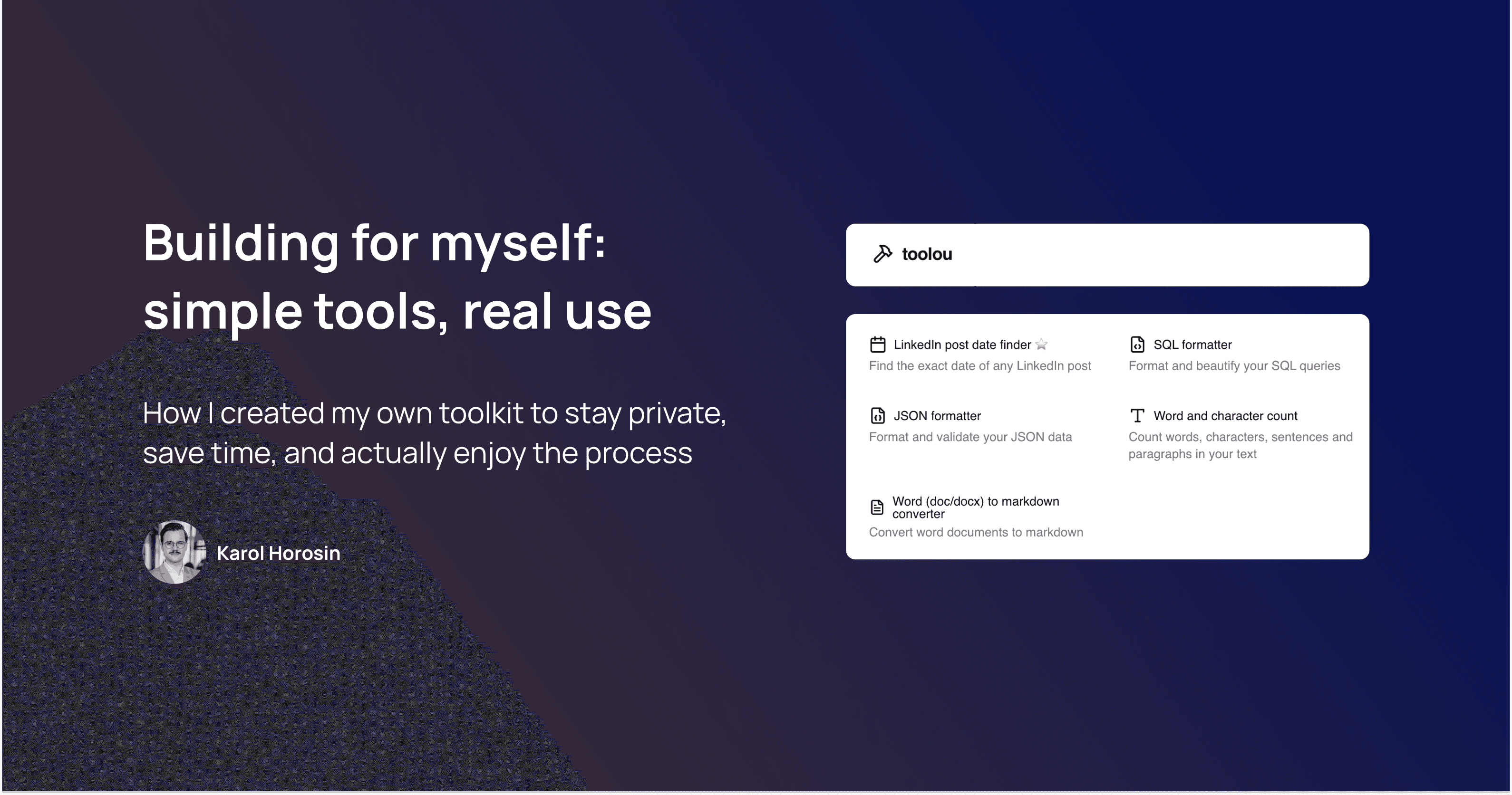
How I created my own toolkit to stay private, save time, and actually enjoy the process
What happens when you let LLMs take over dev for two weeks

V0 as a perfect solution for side projects, simple apps, and fast feedback

Tips for staying sane in big projects

Offline, private coding with Qwen2.5-Coder (or DeepSeek) and Continue

In this blog post, I will share how to use LangChain, a flexible framework for building AI-driven applications, to extract and generate structured JSON data with GPT and Langchain. I'll provide code snippets and concise instructions to help you set up and run the project.
LangChain is a framework designed to speed up the development of AI-driven applications. It provides a suite of components for crafting prompt templates, connecting to diverse data sources, and interacting seamlessly with various tools. It simplifies prompt engineering, data input and output, and tool interaction, so we can focus on core logic. It is available in Python and JavaScript.
LangChain contains tools that make getting structured (as in JSON format) output out of LLMs easy. Let's use them to our advantage.
I am assuming you have one of the latest versions of Python. I've used 3.11. Visit the LangChain website if you need more details.
First, create a new project, i.e.:
Create a new directory for your project and navigate to it in your terminal.
Run pip install langchain openai
Create an index.py file.
Then, let's configure the API keys. Other dependencies are included.
# configure credentials (easiest)
export OPENAI_API_KEY=XXX
This is just for demonstrative use. In production, use your secret management way of choice.
Let's import the required dependencies on top of our python file.
import os
from langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
from typing import List
Let's start with generating some fake data to see the possibilities of parsing.
Sample use case: JSON output formatting for fake identity generation.
First, we need to tell the library, what we want to get. LangChain supports defining expected schema using a popular library Pydantic:
# Define a new Pydantic model with field descriptions and tailored for Twitter.
class TwitterUser(BaseModel):
name: str = Field(description="Full name of the user.")
handle: str = Field(description="Twitter handle of the user, without the '@'.")
age: int = Field(description="Age of the user.")
hobbies: List[str] = Field(description="List of hobbies of the user.")
email: str = Field(description="Email address of the user.")
bio: str = Field(description="Bio or short description about the user.")
location: str = Field(description="Location or region where the user resides.")
is_blue_badge: bool = Field(
description="Boolean indicating if the user has a verified blue badge."
)
joined: str = Field(description="Date the user joined Twitter.")
gender: str = Field(description="Gender of the user.")
appearance: str = Field(description="Physical description of the user.")
avatar_prompt: str = Field(
description="Prompt for generating a photorealistic avatar image. The image should capture the essence of the user's appearance description, ideally in a setting that aligns with their interests or bio. Use professional equipment to ensure high quality and fine details."
)
banner_prompt: str = Field(
description="Prompt for generating a banner image. This image should represent the user's hobbies, interests, or the essence of their bio. It should be high-resolution and captivating, suitable for a Twitter profile banner."
)
To use the auto-generated template, we need to create a LangChain construct called PromptTemplate. In this case we're going to use variation appropriate for a cheap chat model like GPT 3.5. It will contain format instructions from the parser:
# Instantiate the parser with the new model.
parser = PydanticOutputParser(pydantic_object=TwitterUser)
# Update the prompt to match the new query and desired format.
prompt = ChatPromptTemplate(
messages=[
HumanMessagePromptTemplate.from_template(
"answer the users question as best as possible.\n{format_instructions}\n{question}"
)
],
input_variables=["question"],
partial_variables={
"format_instructions": parser.get_format_instructions(),
},
)
To execute the structured output, call the OpenAI model with the input:
chat_model = ChatOpenAI(
model="gpt-3.5-turbo",
openai_api_key=os.getenv("OPENAI_API_KEY"),
max_tokens=1000
)
# Generate the input using the updated prompt.
user_query = (
"Generate a detailed Twitter profile of a random realistic user with a diverse background, "
"from any country in the world, original name, including prompts for images. Come up with "
"real name, never use most popular placeholders like john smith and john doe."
)
_input = prompt.format_prompt(question=user_query)
output = chat_model(_input.to_messages())
parsed = parser.parse(output.content)
print(output.content)
print(parsed)
Here's what will be sent to the AI model. This will most likely change in the future LangChain versions.
Answer the user query.
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here is the output schema:
```
{"properties": {"name": {"description": "Full name of the user.", "title": "Name", "type": "string"}, "handle": {"description": "Twitter handle of the user, without the '@'.", "title": "Handle", "type": "string"}, "age": {"description": "Age of the user.", "title": "Age", "type": "integer"}, "hobbies": {"description": "List of hobbies of the user.", "items": {"type": "string"}, "title": "Hobbies", "type": "array"}, "email": {"description": "Email address of the user.", "title": "Email", "type": "string"}, "bio": {"description": "Bio or short description about the user.", "title": "Bio", "type": "string"}, "location": {"description": "Location or region where the user resides.", "title": "Location", "type": "string"}, "is_blue_badge": {"description": "Boolean indicating if the user has a verified blue badge.", "title": "Is Blue Badge", "type": "boolean"}, "joined": {"description": "Date the user joined Twitter.", "title": "Joined", "type": "string"}, "gender": {"description": "Gender of the user.", "title": "Gender", "type": "string"}, "appearance": {"description": "Physical description of the user.", "title": "Appearance", "type": "string"}, "avatar_prompt": {"description": "Prompt for generating a photorealistic avatar image. The image should capture the essence of the user's appearance description, ideally in a setting that aligns with their interests or bio. Use professional equipment to ensure high quality and fine details.", "title": "Avatar Prompt", "type": "string"}, "banner_prompt": {"description": "Prompt for generating a banner image. This image should represent the user's hobbies, interests, or the essence of their bio. It should be high-resolution and captivating, suitable for a Twitter profile banner.", "title": "Banner Prompt", "type": "string"}}, "required": ["name", "handle", "age", "hobbies", "email", "bio", "location", "is_blue_badge", "joined", "gender", "appearance", "avatar_prompt", "banner_prompt"]}
```
Generate a detailed Twitter profile of a random realistic user with a diverse background, from any country in the world, original name, including prompts for images. Come up with real name, never use most popular placeholders like john smith and john doe.
The output from the model will look like this:
{
"name": "Daniela Kolarova",
"handle": "PragueReveries",
"age": 29,
"hobbies": ["classical piano", "literature", "yoga"],
"email": "daniela.kolarova@czmail.cz",
"bio": "Finding harmony through keys, books, and breaths. Embracing Prague's spellbinding tales.",
"location": "Prague, Czech Republic",
"is_blue_badge": True,
"joined": "2014-05-01",
"gender": "female",
"appearance": "Caucasian, long wavy auburn hair, green eyes, 5'6\"",
"avatar_prompt": "Photorealistic image of a caucasian woman with green eyes, playing a grand piano. Use Olympus PEN-F with a 38mm lens.",
"banner_prompt": "High-resolution depiction of Prague's rooftops, cozy libraries, and serene yoga studios. Samsung Galaxy S20 II.",
}
As you can see, we got just what we needed. We can generate whole identities with complex descriptions matching other parts of the persona.
You may wonder if using LLM in a production application is safe in any way.
If, for example, the output was missing a name, we would get this error:
Got: 1 validation error for TwitterUser
name
none is not an allowed value (type=type_error.none.not_allowed)
Luckily LangChain is focused on problems just like this. In case the output needs fixing, use the OutputFixingParser. It will try and fix errors in case your LLM outputs something not matching your requirements.
from langchain.output_parsers import OutputFixingParser
from langchain.schema import OutputParserException
try:
parsed = parser.parse(output.content)
except OutputParserException as e:
new_parser = OutputFixingParser.from_llm(
parser=parser,
llm=ChatOpenAI()
)
parsed = new_parser.parse(output.content)
Under the hood, LangChain is calling our LLM again to fix the output.
To load and extract data from files using LangChain, you can follow these steps. In this example, we're going to load the PDF file. Conveniently, LangChain has utilities just for this purpose. We need one extra dependency.
pip install pypdf
We're going to load a short bio of Elon Musk and extract the information we've previously generated. Download the PDF file here: google drive.
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("elon.pdf")
document = loader.load()
We need to modify the prompt template to indicate extraction, not generation.
document_query = "Create a profile based on this description: " + document[0].page_content
_input = prompt.format_prompt(question=document_query)
output = chat_model(_input.to_messages())
parsed = parser.parse(output.content)
print(parsed)
Thanks to these modifications, we get the following output:
{
"name": "Elon Musk",
"handle": "elonmusk",
"age": 51,
"hobbies": ["space exploration", "electric vehicles", "artificial intelligence", "sustainable energy", "tunnel construction", "neural interfaces", "Mars colonization", "hyperloop transportation"],
"email": "elonmusk@gmail.com",
"bio": "Entrepreneur, inventor, and CEO. Revolutionizing transportation and energy.",
"location": "Pretoria, South Africa",
"is_blue_badge": false,
"joined": "2008-06-02",
"gender": "male",
"appearance": "normal build, short-cropped hair, trimmed beard",
"avatar_prompt": "Generate a photorealistic avatar image capturing Elon Musk's appearance. The image should align with his interests and bio.",
"banner_prompt": "Generate a high-resolution banner image representing Elon Musk's various fields of interest."
}
By following these steps, we've extracted structured JSON data from a PDF file! This approach is versatile and can be adapted to suit your specific use case.
In conclusion, by leveraging LangChain, GPTs, and Python, we can reduce the complexity of our LLM apps and introduce useful error handling.
You can find the code for this tutorial on GitHub: link.
Don't forget to follow me on Twitter @ horosin_ and subscribe to my newsletter for more tips and insights!
If you don't have Twitter, you can also follow me on LinkedIn.