Extracting and Generating JSON Data with GPTs, LangChain, and Node.js
Manipulating Structured Data (from PDFs) with the Model behind ChatGPT, LangChain, and Node.js for Powerful AI-driven Applications

K
Engineer, Builder, Writer
Search for a command to run...
Manipulating Structured Data (from PDFs) with the Model behind ChatGPT, LangChain, and Node.js for Powerful AI-driven Applications
Engineer, Builder, Writer
Great article. How can we extend this to handle the entire PDF? I need to generate a JSON object with information scattered across multiple pages of the PDF
How big of a pdf? Several approaches possible
Yeah, it is inspiring, I have so many ideas for using this. I hope for advancements with local LLMs and hardware though, you can't apply this tech yo to the sensitive data where it would be very helpful
It pretty much enables programming with natural language!
In this blog series, we explore the transformative potential of artificial intelligence tools and models in software development and other fields via tutorials and case studies.
Streamlining PowerPoint Presentation Creation with ChatGPT and MARP
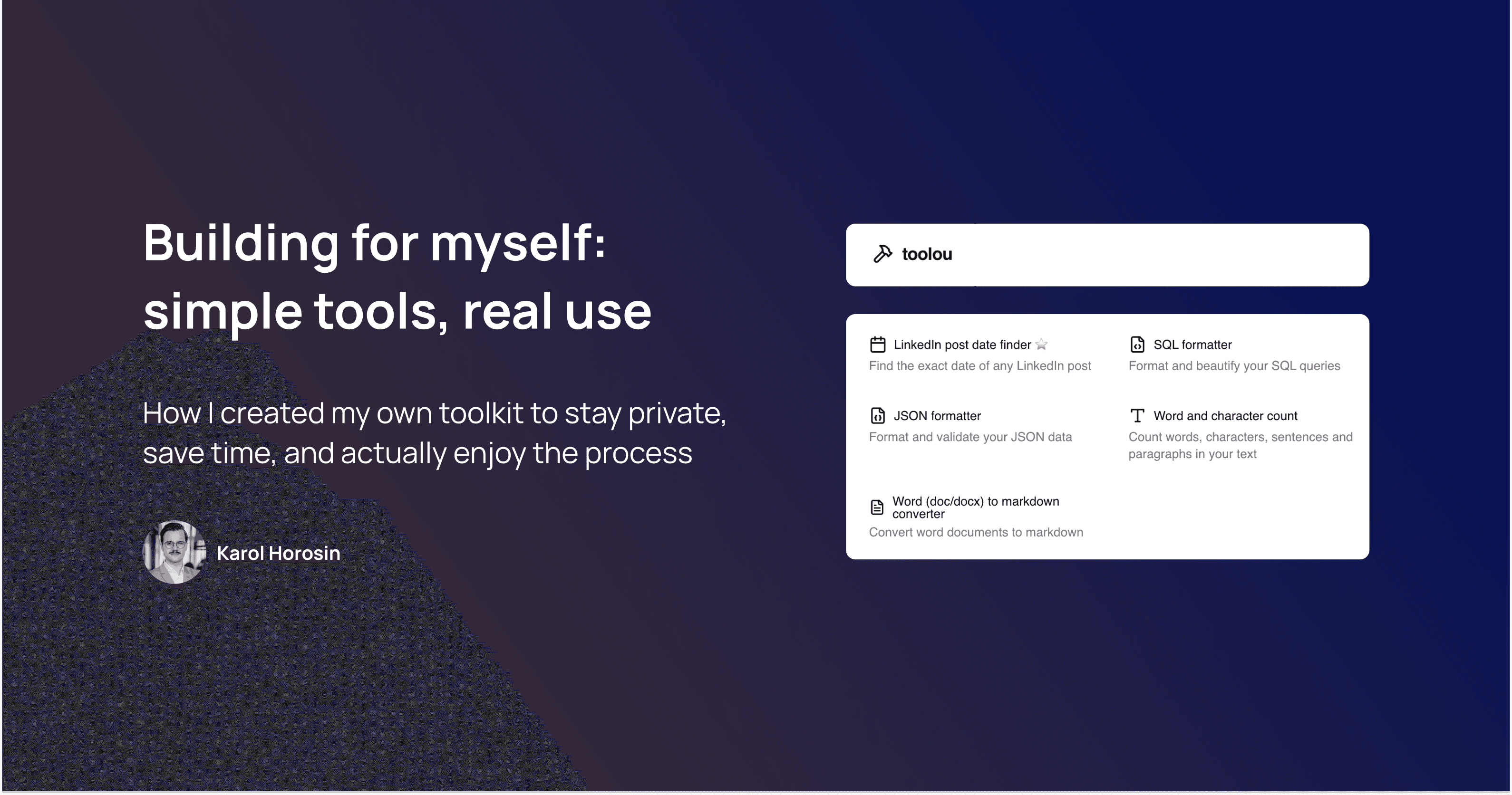
How I created my own toolkit to stay private, save time, and actually enjoy the process
What happens when you let LLMs take over dev for two weeks

V0 as a perfect solution for side projects, simple apps, and fast feedback

Tips for staying sane in big projects

Offline, private coding with Qwen2.5-Coder (or DeepSeek) and Continue

In this blog post, I will share how to use LangChain, a flexible framework for building AI-driven applications, to extract and generate structured JSON data with GPTs and Node.js. I'll provide code snippets and concise instructions to help you set up and run the project.
LangChain is an innovative and versatile framework designed to streamline the development of AI-driven applications. With its modular architecture, it provides a comprehensive suite of components for crafting prompt templates, connecting to diverse data sources, and interacting seamlessly with various tools. By simplifying prompt engineering, data source integration, and tool interaction, LangChain enables developers to focus on core application logic, accelerating the development process. Available in both Python and JavaScript APIs, LangChain is highly adaptable, empowering developers to harness the power of natural language processing and AI across multiple platforms and use cases.
LangChain contains tools that make getting structured (as in JSON format) output out of LLMs east. Let's use them to our advantage.
I am assuming you have one of the latest versions of NodeJS. I've used node 18. Visit LangChain website if you need more details.
First, create a new node project, i.e.:
Create a new directory for your project and navigate to it in your terminal.
Run npm init to initialize a new Node.js project.
Create an index.js file.
Then, let's install LangChain and configure the API keys. Other dependencies are included.
npm i langchain
# configure credentials (easiest)
export OPENAI_API_KEY=XXX
export SERPAPI_API_KEY=XXX
This is just for demonstrative use. I prefer not to export variables, I am using popular dotenv npm library instead.
Let's import the required dependencies on top of our JS file.
import { z } from "zod";
import { OpenAI } from "langchain/llms/openai";
import { PromptTemplate } from "langchain/prompts";
import {
StructuredOutputParser,
OutputFixingParser,
} from "langchain/output_parsers";
Let's start with generating some fake data to see the possibilities of parsing.
First, we need to tell the library, what we want to get. LangChain supports defining expected schema using a popular library called Zod:
const parser = StructuredOutputParser.fromZodSchema(
z.object({
name: z.string().describe("Human name"),
surname: z.string().describe("Human surname"),
age: z.number().describe("Human age"),
appearance: z.string().describe("Human appearance description"),
shortBio: z.string().describe("Short bio secription"),
university: z.string().optional().describe("University name if attended"),
gender: z.string().describe("Gender of the human"),
interests: z
.array(z.string())
.describe("json array of strings human interests"),
})
);
To use this template, we need to create a LangChain construct called PromptTemplate. It will contain format instructions from the parser:
const formatInstructions = parser.getFormatInstructions();
const prompt = new PromptTemplate({
template:
`Generate details of a hypothetical person.\n{format_instructions}
Person description: {description}`,
inputVariables: ["description"],
partialVariables: { format_instructions: formatInstructions },
});
To execute the structured output, call the OpenAI model with the input:
const model = new OpenAI({ temperature: 0.5, model: "gpt-3.5-turbo" });
const input = await prompt.format({
description: "A man, living in Poland",
});
const response = await model.call(input);
Here's what will be sent to the AI model. This will most likely change in the future LangChain versions.
Generate details of a hypothetical person.
You must format your output as a JSON value that adheres to a given "JSON Schema" instance.
"JSON Schema" is a declarative language that allows you to annotate and validate JSON documents.
For example, the example "JSON Schema" instance {{"properties": {{"foo": {{"description": "a list of test words", "type": "array", "items": {{"type": "string"}}}}}}, "required": ["foo"]}}}}
would match an object with one required property, "foo". The "type" property specifies "foo" must be an "array", and the "description" property semantically describes it as "a list of test words". The items within "foo" must be strings.
Thus, the object {{"foo": ["bar", "baz"]}} is a well-formatted instance of this example "JSON Schema". The object {{"properties": {{"foo": ["bar", "baz"]}}}} is not well-formatted.
Your output will be parsed and type-checked according to the provided schema instance, so make sure all fields in your output match exactly!
Here is the JSON Schema instance your output must adhere to:
'''json
{"type":"object","properties":{"name":{"type":"string","description":"Human name"},"surname":{"type":"string","description":"Human surname"},"age":{"type":"number","description":"Human age"},"appearance":{"type":"string","description":"Human appearance description"},"shortBio":{"type":"string","description":"Short bio secription"},"university":{"type":"string","description":"University name if attended"},"gender":{"type":"string","description":"Gender of the human"},"interests":{"type":"array","items":{"type":"string"},"description":"json array of strings human interests"}},"required":["name","surname","age","appearance","shortBio","gender","interests"],"additionalProperties":false,"$schema":"http://json-schema.org/draft-07/schema#"}
'''
Person description: A man, living in Poland.
The output from the model will look like this:
{
"name": "Adam",
"surname": "Kowalski",
"age": 21,
"appearance": "Adam is a tall and slim man with short dark hair and blue eyes.",
"shortBio": "Adam is a 21 year old man from Poland. He is currently studying computer science at the University of Warsaw.",
"university": "University of Warsaw",
"gender": "Male",
"interests": ["Computer Science", "Cooking", "Photography"]
}
As you can see, we got just what we needed. We can generate whole identities with complex descriptions matching other parts of the persona. If we needed to enrich our mock dataset, we could then ask another AI model to generate a photo based on the appearance.
You may wonder if using LLM in a production application is safe in any way. Luckily LangChain is focused on problems just like this. In case the output needs fixing, use the OutputFixingParser. It will try and fix errors in case your LLM outputs something not matching your requirements.
try {
console.log(await parser.parse(response));
} catch (e) {
console.error("Failed to parse bad output: ", e);
const fixParser = OutputFixingParser.fromLLM(
new OpenAI({ temperature: 0, model: "gpt-3.5-turbo" }),
parser
);
const output = await fixParser.parse(response);
console.log("Fixed output: ", output);
}
To load and extract data from files using LangChain, you can follow these steps. In this example, we're going to load the PDF file. Conveniently, LangChain has utilities just for this purpose. We need one extra dependency.
npm install pdf-parse
We're going to load a short bio of Elon Musk and extract the information we've previously generated. Download the PDF file here: google drive.
First, let's create a new file, e. g. structured-pdf.js. Let's start with loading the PDF.
import { PDFLoader } from "langchain/document_loaders/fs/pdf";
const loader = new PDFLoader("./elon.pdf");
const docs = await loader.load();
console.log(docs);
We need to modify the prompt template to indicate extraction, not generation. I also had to modify a prompt to fix the JSON rendering issue, as the results were inconsistent at times.
const prompt = new PromptTemplate({
template:
"Extract information from the person description.\n{format_instructions}\nThe response should be presented in a markdown JSON codeblock.\nPerson description: {inputText}",
inputVariables: ["inputText"],
partialVariables: { format_instructions: formatInstructions },
});
Finally, we need to extend the output length we allow (it's a bit more data than in the generated case), as the default is 256 tokens. We also need to call the model using our loaded document, not a predetermined person description.
const model = new OpenAI({ temperature: 0.5, model: "gpt-3.5-turbo", maxTokens: 2000 });
const input = await prompt.format({
inputText: docs[0].pageContent,
});
Thanks to these modifications, we get the following output:
{
name: 'Elon',
surname: 'Musk',
age: 51,
appearance: 'normal build, short-cropped hair, and a trimmed beard',
// truncated by me
shortBio: "Elon Musk, a 51-year-old male entrepreneur, inventor, and CEO, is best known for his...',
gender: 'male',
interests: [
'space exploration',
'electric vehicles',
'artificial intelligence',
'sustainable energy',
'tunnel construction',
'neural interfaces',
'Mars colonization',
'hyperloop transportation'
]
}
By following these steps, we've extracted structured JSON data from a PDF file! This approach is versatile and can be adapted to suit your specific use case.
In conclusion, by leveraging LangChain, GPTs, and Node.js, you can create powerful applications for extracting and generating structured JSON data from various sources. The potential applications are vast, and with a bit of creativity, you can use this technology to build innovative apps and solutions.
You can find the code for this tutorial on GitHub: link.
Don't forget to follow me on Twitter @ horosin_ and subscribe to my newsletter for more tips and insights!
If you don't have Twitter, you can also follow me on LinkedIn.