Fine-tuning OpenAI GPT 3.5: Practical example with Python
Hands-on example and tutorial to achieve shorter prompts, better performance and save money on your API calls. All using synthetic data from GPT-4.

Engineer, Builder, Writer
Fine-tuning is now available for one of the key models offered by OpenAI. Up to this point, we were only able to fine-tune older model variants with performance subpar to the likes of GPT-3.5 and GPT-4. Maximizing the performance of OpenAI's models without draining your budget is now achievable.
Why fine-tune?
Better responses
Training with more examples than in few-shot-learning approaches (giving a few examples in the prompt)
Shorter prompts - lower costs and latency
OpenAI also lists the following benefits: improved steerability, reliable output formatting and custom tone.
You can find all of the code from this article on GitHub: link. The code is experimental and several-use-only, don't expect it to be polished.
Please remember that for JSON output it may be better to use function calling functionality. That said, this tutorial should show you how to fine-tune in general.
Sample use case: JSON output formatting for fake identity generation
Using large language models for tasks like JSON output formatting often results in lengthy and costly prompts. Let's explore this challenge with a sample use case.
I am a big fan of using large language models (LLMs) like GPT-4 for language processing. Many people use the popular library Langchain for this use case (and I wrote about it), while others use native function calling features (I made a short demo). Both of these use additional tokens and are error-prone.
Let's look at a particular example. Let's assume we often need to generate people's identities in structured formats to seed our demo databases, populate dashboards at development stages, etc. Let's take typically Twitter/X user profile and try to generate its parts.
{
"name": "John Doe",
"handle": "jdoe",
"age": 30,
"hobbies": ["programming", "gaming", "reading"],
"email": "john.doe@gmail.com",
"bio": "Avid Python programmer and gamer",
"location": "USA",
"is_blue_badge": True,
"joined": "2019-01-01",
"gender": "male",
"appearance": "white, brown hair, brown eyes, 6'0",
"avatar_prompt": "A photorealistic image of a man, white, brown hair, brown eyes, against a blurred backdrop od a home scenery. Use a Hasselblad camera with a 85mm lens at F 1.2 aperture setting and soft sunlight falling on the subject to capture the subject’s creativity.",
"banner_prompt": "High resolution photo of a desk with a laptop, a gamepad and a book. Canon DSLR."
}
The prompt to achieve that with high degree of success is very long, especially using Langchain templates, have a look:
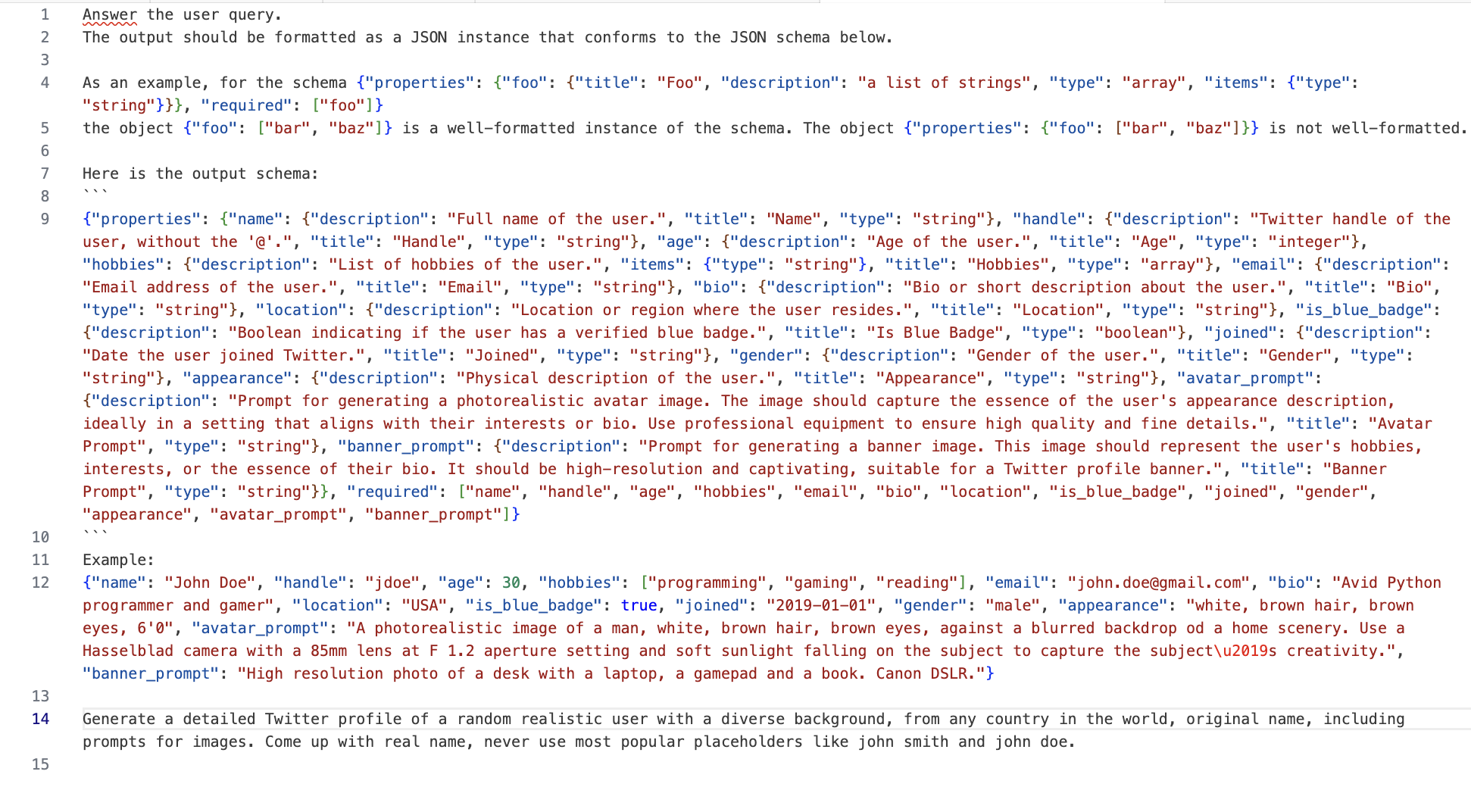
That is 923 tokens for the input and the output takes 236. Generating a thousand would cost us $41.85 with GPT-4. With GPT 3.5 we could do it for $1.85. If the promise of fine-tuning can be met and we get performance closer to GPT-4 with shorter prompts, we will save tons of money. Most of the use cases require more data.
What we can try to do is to reduce the prompt by fine-tuning to the following:
As a response, provide the following fields in a JSON dict: name, handle, age, hobbies, email, bio, location, is_blue_badge, joined, gender, appearance, avatar_prompt, and banner_prompt.
Generate details of a random Twitter profile.
With this prompt and fine-tuned model, we would pay $4.388. 10x less than GPT-4 but almost 3x GPT-3.5. The fine-runing costs in this tutorial amount to around $0.4.
Let's see how this works out. I have no automatic way of comparing the quality of the generated results but if you know of any research, please let everyone know in the comment.
The code to generate this prompt can be found in the project repository.
Preparing the synthetic training data
Make sure you have the latest version of the openai package by running pip install -U -r requirements.txt.
You also need to include your OpenAPI key in the environment variable. export OPENAI_API_KEY="XXXXX".
Let's use GPT-4 to prepare 50 examples as per minimum OpenAI requirements. It will cost us around $2.4. We're leveraging the power of GPT-4 for high-quality examples to train our model.
import openai
import json
prompt = "COMPLICATED LONG PROMPT"
SAMPLE_COUNT = 50
examples = []
for i in range(SAMPLE_COUNT):
chat_completion = openai.ChatCompletion.create(
model="gpt-4", messages=[{"role": "user", "content": prompt}]
)
print(chat_completion.choices[0].message.content)
examples.append(json.loads(chat_completion.choices[0].message.content))
with open("training_examples.json", "w") as outfile:
outfile.write(json.dumps(examples))
Now, armed with 50 strong examples from GPT-4, we can fine-tune our 3.5 model.
Data formatting
OpenAI suggests using the system message for the input data. It uses a system prompt as a recommended way of passing general instructions. Let's construct our template message.
{
"messages": [
{
"role": "system",
"content": "As a response, provide the following fields in a JSON dict: name, handle, age, hobbies, email, bio, location, is_blue_badge, joined, gender, appearance, avatar_prompt, and banner_prompt."
},
{
"role": "user",
"content": "Generate details of a random Twitter profile."
},
{
"role": "assistant",
"content": f"{profile_details}"
}
We also need to prepare a file with each JSON object in a new line and run it through a validator provided by OpenAI.
transform_data.py
import json
# Load the data from the json file
with open('training_examples.json', 'r') as f:
profiles = json.load(f)
# Output file to save the formatted messages
with open('mydata.jsonl', 'w') as out_file:
for profile in profiles:
profile_details = json.dumps(profile)
# Create the desired format
formatted_message = {
"messages": [
{
"role": "system",
"content": "As a response, provide the following fields in a JSON dict: name, handle, age, hobbies, email, bio, location, is_blue_badge, joined, gender, appearance, avatar_prompt, and banner_prompt."
},
{
"role": "user",
"content": "Generate details of a random Twitter profile."
},
{
"role": "assistant",
"content": profile_details
}
]
}
# Write the formatted message to the output file, each on a new line
out_file.write(json.dumps(formatted_message) + "\n")
Now, let's run the formatting script (in the repository called openai_formatting.py.
python openai_formatting.py
You should get the following message.
0 examples may be over the 4096 token limit, they will be truncated during fine-tuning
Dataset has ~14194 tokens that will be charged for during training
By default, you'll train for 3 epochs on this dataset
By default, you'll be charged for ~42582 tokens
See pricing page to estimate total costs
In our case, fine-tuning will cost $0.34.
Fine-tuning the model
I have compiled all the necessary calls into one file. The script uploads the file with our data, waits for it to process, and then starts the finetuning process. Be careful, running it will incur costs!
finetune.py
import os
import openai
import time
openai.api_key = os.getenv("OPENAI_API_KEY")
file_upload = openai.File.create(file=open("mydata.jsonl", "rb"), purpose="fine-tune")
print("Uploaded file id", file_upload.id)
while True:
print("Waiting for file to process...")
file_handle = openai.File.retrieve(id=file_upload.id)
if len(file_handle) and file_handle.status == "processed":
print("File processed")
break
time.sleep(3)
job = openai.FineTuningJob.create(training_file=file_upload.id, model="gpt-3.5-turbo")
while True:
print("Waiting for fine-tuning to complete...")
job_handle = openai.FineTuningJob.retrieve(id=job.id)
if job_handle.status == "succeeded":
print("Fine-tuning complete")
print("Fine-tuned model info", job_handle)
print("Model id", job_handle.fine_tuned_model)
break
time.sleep(3)
Run it by typing python finetune.py.
If you don't want to wait, stop the script and wait to receive an email from OpenAI.
Both the message in the terminal and the email will include the model id! Now let's test it!
Testing the model
Let's prepare the test file. Replace model_id with yours.
run_model.py
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
model_id = "ft:gpt-3.5-turbo:my-org:custom_suffix:id"
completion = openai.ChatCompletion.create(
model=model_id,
messages=[
{
"role": "system",
"content": "As a response, provide the following fields in a JSON dict: name, handle, age, hobbies, email, bio, location, is_blue_badge, joined, gender, appearance, avatar_prompt, and banner_prompt.",
},
{"role": "user", "content": "Generate details of a random Twitter profile."},
],
)
print(completion.choices[0].message)
python run_model.py
And we should receive an output similar to this!
{
"name": "Daniela Kolarova",
"handle": "PragueReveries",
"age": 29,
"hobbies": ["classical piano", "literature", "yoga"],
"email": "daniela.kolarova@czmail.cz",
"bio": "Finding harmony through keys, books, and breaths. Embracing Prague's spellbinding tales.",
"location": "Prague, Czech Republic",
"is_blue_badge": True,
"joined": "2014-05-01",
"gender": "female",
"appearance": "Caucasian, long wavy auburn hair, green eyes, 5'6\"",
"avatar_prompt": "Photorealistic image of a caucasian woman with green eyes, playing a grand piano. Use Olympus PEN-F with a 38mm lens.",
"banner_prompt": "High-resolution depiction of Prague's rooftops, cozy libraries, and serene yoga studios. Samsung Galaxy S20 II.",
}
As you can see, we've achieved our goal of generating high-quality data fitting complex instructions with shorter prompts. We didn't measure the quality, so make sure in your use case, this makes sense and is cost-effective.
Conclusion
Fine-tuning has opened up an avenue to achieve more specific and consistent outputs from OpenAI's models. As demonstrated with the Twitter profile generation example, fine-tuning meets the promise of achieving specific outputs with short prompts.
While fine-tuning offers precision, it demands carefully crafted training data to ensure the model doesn't just memorize examples. This process involves initial investments in terms of time and money (luckily, we can generate fine-tuning data with more capable models). Moreover, the quality of outputs should be continuously assessed to ensure they meet the required standards.
For businesses or projects that rely heavily on the performance of LLMs like GPT-4, fine-tuning presents a viable option to optimize performance and cost.
As with any technology, it's crucial to stay updated with the best practices and latest developments in the field. OpenAI continues to evolve its offering, and adopting a flexible approach ensures that you can leverage the best capabilities of these models for your specific needs.
You can find the code for this tutorial on GitHub: link.
Don't forget to follow me on Twitter @ horosin_ and subscribe to my newsletter for more tips and insights!
If you don't have Twitter, you can also follow me on LinkedIn.